A query is a request for information from a database. It is the basic element of any report.
Query: A request for information from the database.
Report: A script that runs several queries built upon the results of the previous query. It is possible to use the information retrieved from the queries for more complex functions, such as analytics.
Results: The response from the database after executing a query or report.
A query uses a defined set of parameters and operators that allow the user to search a database. Perfect Search query language is designed to support both a simple word list query, much like a search done on the Internet, as well as a Boolean expression query.
Submitting a Query
The simplest way to query the server is through the Report Builder. Below is the simplest form of a query. The query can be typed in the Search for field of Single query and formatted in the following manner:
()Query expression
The simplest form of a query line in a compound report is below:
variable = wrapper_function('()query expression')
If the query is not working as expected, it may be because of an error in the query itself. Verify that everything has been entered correctly. Below are some common entry errors:
- Not opening or closing the search criteria with the proper number of quotation marks, parentheses–(), brackets–[], or braces–{}
- Making the search too narrow or too large
- Not capitalizing the Boolean operators
- Not including the colon after the field names in a Boolean search
- Misspelling field names
- Selecting the wrong store
- Not surrounding the entire query expression with quotes in compound reports
Unless otherwise noted, the examples are given as they are entered in a compound report with Boolean expressions. Replace variable with the query name. Replace wrapper_function with the appropriate function. Replace query_expression with the appropriate terms.
If doing a search by entering the query in the search bar of the browser, enter the search as below:
https://appliance_ip/search?q=query_expression¶meter
Query Expression
A query expression is the q parameter and involves logical operators and parentheses. Terms comprise the basic elements of a search. Terms can be words, simple phrases, or a field name that is followed by a value. When a term consists of only a simple word or phrase, it is considered a hit if it is found anywhere within the document. If it is qualified by a field name, the search is constrained to only values under that field name.
The expression may consist of two parts: ranked terms and Boolean expressions. Ranked terms are single words or phrases but cannot contain field names. Boolean expressions may contain single words, phrases, and field names. A query expression can be pure ranked, pure Boolean, or contain both ranked and Boolean components.
Formatting
Correct formatting of each expression is important. If the query does not have the correct format, an error could occur or incorrect information could be returned.
- Quotation marks are necessary on a term when phrases must appear in the document to be a hit; without the quotation marks surrounding the phrase, the individual words can be separated and found anywhere within the document.
- Parentheses are required when doing a Boolean search. Each element opened with a parenthesis must also be closed with one.
- The Boolean operators (AND, OR, NOT, etc.) must be capitalized.
- Colons must be used after a field name and SET.
In the example below, the terms diabetes and "john smith" are ranked search terms. The Boolean expression, n.age:[20 TO 30] s.sending_facility:"timpview hospital", is surrounded by parentheses and contains terms whose field values must match identically for a record to qualify as a hit. Notice the use of the single quotes around the entire query expression and double quotes around the phrases where the words must remain together to be a hit.
Example:
variable = wrapper_function('diabetes "john smith" (n.age:[20 TO 30] s.sending_facility:"timpview hospital")')
Ranked Searches
The search appliance allows results to be ranked by how well the hits match the search terms, much like a search on the Internet. A term found in the title ranks higher than a term in the description of a document. A term located in the body scores lowest. The terms are considered "fuzzy" because they can occur anywhere in the document. Also, ranked terms search for stem words and close, but inexact, phrases.
If several words, a phrase, and a Boolean expression are part of a search query, the search engine first determines if the words exist in the document, followed by the phrase, and finally the Boolean expression. All terms must appear in the document to be considered a hit.
A ranked search may be done without a Boolean expression.
Example:
variable = wrapper_function('cholesterol plaque positive "heart attack" ("mortally high" AND "immediate concern")')
Ranked vs. Boolean
If the preceding expression had been written as pure Boolean, the hits would be the same as above, but the order they appeared in would be different because of the ranking.
Ranked searches tend to be slower than pure Boolean searches.
Boolean Searches
The Boolean syntax used in the search appliance is Lucene-like. They can contain as many terms as desired, but the expression must begin with an opening parenthesis and must likewise close with a parenthesis. Boolean expressions are logically rigorous and only return hits that exactly fulfill their expression. Boolean searches typically run faster than ranked searches.
The Boolean operators field, metaphone, stemming, content, number, and date fields must be configured in the parse table prior to indexing to be used in searches. Fields are useful to limit searches and results because when a field is used in the Boolean search, the terms must be located within those fields. If the field parameter is not used, a hit may be returned if the term is located anywhere in the document rather than in the targeted field.
Entering fields as part of the Boolean expression currently requires an additional Hungarian notation: s, d, h, or n. We have added a fifth prefix, v. Know that any field that has a prefix of s can also use h or v.
- s: The string prefix is intended for text fields such as names.
cisco = get_hits('()s.sending_facility:"Cisco"') # It will return "Cisco", "Cisco Corp", "Cisco Labs", and any other facility with "Cisco" in it.
- d: This is intended for date fields, such as date of service or birth date.
date = get_hits('()n.date_of_service:[20250501 TO 20250531])
- n: The number prefix is intended for numeric fields, such as age.
variable = wrapper_function('()n.age:[46 TO 100]')
- h: The hierarchy prefix is intended for paths or partial paths, but can be used with text matches.
github = get_hits('()h.sending_application:"https://github.com"') # This returns all paths that begin "https://github.com"
- v: The value prefix is an exact match for the value entered, this includes punctuation but is not case-sensitive.
ciscoinc = get_hits('()v.sending_facility:"Cisco, Inc"') # This returns all facilities that are "Cisco, Inc" only.
If help is needed in knowing which to use, clicking Add Fields in the Builder section in the Single reports tab may help.
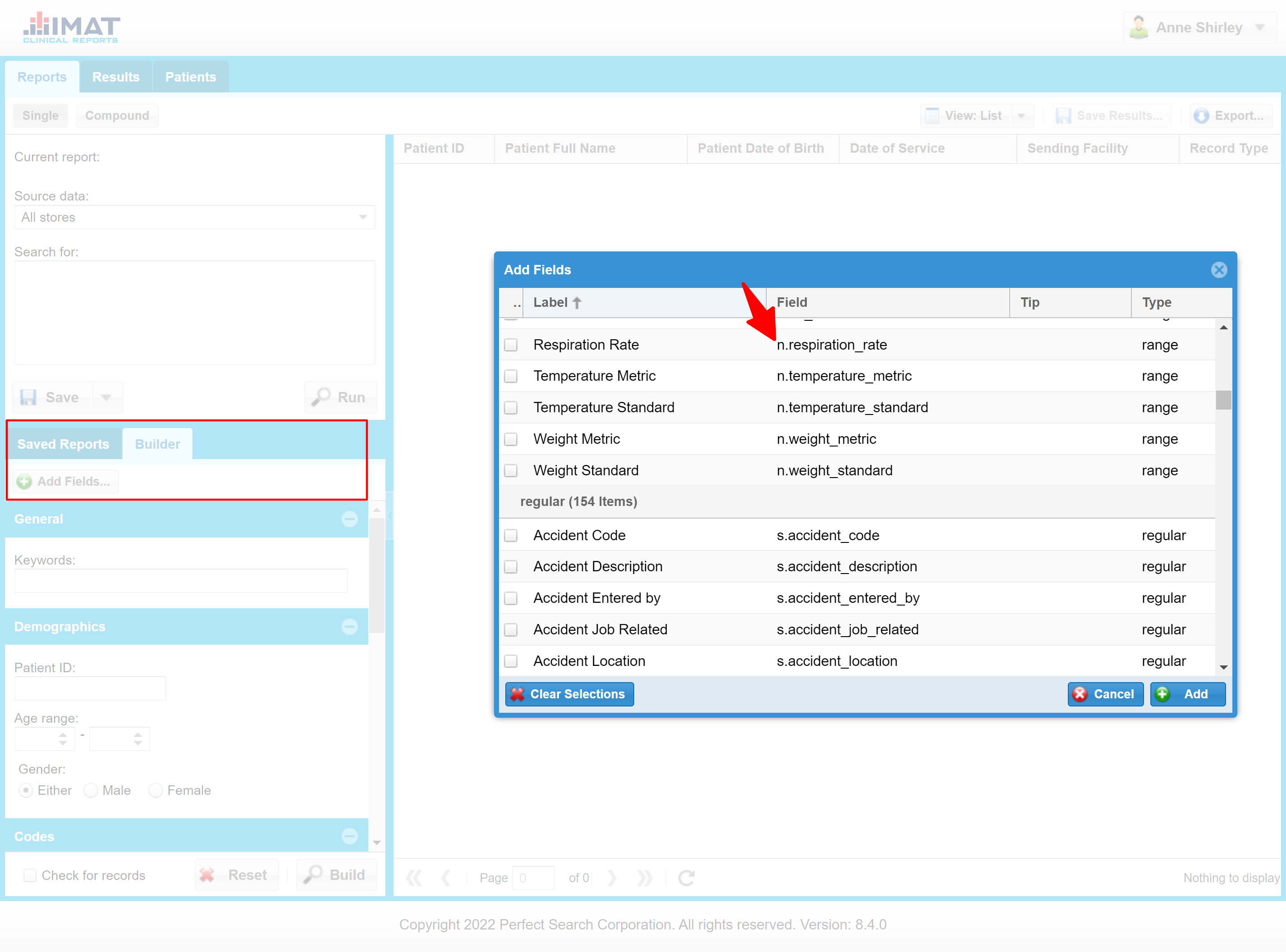
Some examples throughout the Boolean section do not have the Hungarian notation because they do not reflect actual field names.
Parameters
- parentheses
- NOT, OR, AND
- IN
- FOR
- Field:value
- Phrase
- Numeric Search
- Date-time Search
- COMBO
- SET
- FILTER
- Symbols
- Doclang
Parentheses
Parentheses, (), are used to indicate a Boolean search and to control nesting of search terms. Fifty levels of nesting are supported. Parentheses or brackets must occur as a set: if a left parenthesis starts an expression or a grouping, a right parenthesis must end the same expression or grouping.
Example:
variable = wrapper_function('(Smith AND John)')
Parentheses can be grouped together at the beginning of the Boolean expression to achieve the same effect. The examples throughout this document use both methods; either is acceptable.
Example:
variable = wrapper_function('()Smith AND John')
Boolean NOT, OR, AND
Parentheses can also be used to explicitly specify the Boolean operator precedence. When grouping parentheses that specify the binding are absent, NOT binds first, then OR, and lastly AND. (Note this is different than computer programming languages, where AND binds at a higher precedence than OR.)
The following two examples return the same results:
Examples:
variable = wrapper_function('(Smith AND (John OR William))')
variable = wrapper_function('(Smith AND John OR William)')
Parentheses can be used to specify the Boolean operator precedence when the default operator hierarchy is not intended.
Example:
variable = wrapper_function('((Smith AND John) OR Jones NOT Davy)')
NOT
Binary Boolean NOT searches for documents that contain the first term and do not contain the second term. The returned document must meet both requirements.
OR
Boolean OR searches documents for either term. The results for the query contain at least one of the terms provided but can cantain all terms.
AND
Boolean AND searches require all of the terms to be present in each result.
In a Boolean expression, sub-terms without an explicit operator default to a logical AND operation. The following two examples return the same results.
Examples:
variable = get_hits('()diabetes kidney')
variable = get_hits('()diabetes AND kidney')
IN
Boolean IN can be used instead of making large OR expressions of values and searches for any of the values listed. Each term must be separated by a comma. IN can only contain phrases or single words. Field names cannot be used inside an IN list. However, a field name may be used outside of the IN expression, restricting the search for the terms to be contained within the field name. IN may also be used with symbol names as values.
Example:
variable = wrapper_function('()IN(diabetes,"heart disease","heart attack")')
Examples:
variable = wrapper_function('()fieldname:IN(term1, term2,"term3 phrase")')
holiday_names = get_hits('()s.patient_first_name:IN(holly, valentine, epiphany)')
FOR
The FOR function automatically creates a union across listed fields that use the same value expression. This reduces the need for a large OR expression and eliminates typing the same value expression multiple times. FOR applies the value expression to each of the fields provided. Fields must be defined in the parse table. The following queries return the same results using the same value expression (val_expr):
Examples:
variable = wrapper_function('(field1:(val_expr) OR field2:(val_expr) OR field3:(val_expr) OR field4:(val_expr) OR field5(val_expr))')
variable = wrapper_function('()FOR(field1, field2, field3, field4, field5):(val_expr)')
Automatic concatenation can occur across an inner list of field name pieces to create a list of full field names. Use the braces, {}, for the inner list. The following queries return the same results:
Examples:
variable = wrapper_function('()FOR(xxx.{a, b, c}.yyy):(val_expr)')
variable = wrapper_function('()xxx.a.yyy:(val_expr) OR xxx.b.yyy:(val_expr) OR xxx.c.yyy:(val_expr)')
Symbols, indicated by angle brackets, <>, may also be used. The symbol is found in the symbol map, and the stored list of field name pieces is retrieved. For example, if the symbol <a> resolved to the list {a1, a2, a3}, the following queries return the same results:
Examples:
variable = wrapper_function('()FOR(xxx<a>yyy):(val_expr)')
variable = wrapper_function('()xxx.a1.yyy:(val_expr) OR xxx.a2.yyy:(val_expr) OR xxx.a3.yyy:(val_expr)')
A mixed inner list of symbols and field name pieces may be used as a parameter. The following queries get the same results:
Examples:
variable = wrapper_function('()FOR(xxx.{<a>, b, c}.yyy:(val_expr))')
variable = wrapper_function('(xxx.a1.yyy:(val_expr) OR xxx.a2.yyy:(val_expr) OR xxx.a3.yyy:(val_expr) OR xxx.b.yyy:(val_expr) OR xxx.c.yyy:(val_expr))')
Complex parameters and simple field name parameters may be intermixed. However, such complexity is rare since a good symbol definition already contains the complete list.
Example:
variable = wrapper_function('()FOR(field1, xxx.{<a>, b, c}, field2, zzz.{<sym1>, <cat.sym2>}, field3):(val_expr))')
Field:value
Fields are defined in the parse table as data to be indexed when a document is fed. The value is the query term, phrase or value expression. Field values must match exactly: a search with the value "Mountain" does not find those that have a value of "Mountain Valley Hospital".
The following search queries the sending_facility field for a string.
Examples:
variable = wrapper_function('(s.sending_facility:"smith")')
variable = get_hits('()s.patient_full_name:(john OR smith)')
The following query searches the facility_id field for the facility with the ID of 34156.
Example:
variable = wrapper_function('(n.facility_id:[34156])')
Field:value~M
The metaphone search uses a double metaphone algorithm and returns words that sound like the search term entered. Add ~M to the end of the field to perform a metaphone search.
Field:value~S
A stemmed search takes the root of the searched word and finds similar words from the root of the searched word. Add ~S to the end of the field. Adding only a tilde, ~, produces the same results as ~S.
Phrase
The quotes around a string of words indicate a phrase search. A phrase search searches for the entire phrase and not the presence of individual words.
Example:
variable = wrapper_function('"to be or not to be"')
"phrase"~S
The stemmed phrase search searches for stem variations of the words in the phrase. The phrase search must be coordinated with the parse table to create the stemmed versions of the terms in the phrase at index creation. Add ~S outside the quotation marks to the perform a stemmed search.
"phrase"~M
The double metaphone phrase search searches for all words in the phrase that sound similar to the words in the phrase.
"phrase"~C
The content phrase search ignores ordering and stop words.
"phrase"~CS
The content stemmed phrase search combines the stemmed search and the content search. Adding only a tilde, ~, produces the same results as ~CS.
"phrase"~CM
The content metaphone phrase search combines the metaphone search and the content search.
Numeric Search
A query can search a number range of a variable in the Boolean search portion of the search. The field must be defined in the parsetable.xml as a number field prior to searching. Use the operator TO to indicate the span of the search.
Specific characters determine the results:
- Square brackets, [], return the boundary terms specified in the search.
- Braces, {}, exclude the boundary terms.
- Combine the two and include one boundary and exclude another.
- An asterisk, *, creates an unlimited boundary or boundaries.
- Combine any of these symbols to customize the search.
A numeric range search that includes boundary numbers is below:
Example:
variable = wrapper_function('(n.height_standard:[60 TO 65])')
The above query returns results that have one of the following heights in the field height:
60,61,62,63,64,65
Date-time Search
A query can search for a date-time range of a variable in the Boolean search portion of the search. In order to work, the field must be defined in the parsetable.xml as a date or datetime field. Use the operator TO to indicate the span of the search.
As with the numeric search, specific characters determine the results:
- Square brackets, [], return the boundary terms specified in the search.
- Braces, {}, exclude the boundary terms.
- Combine the two and include one boundary and exclude another.
- An asterisk, *, creates an unlimited boundary or boundaries.
- Combine any of these symbols to customize the search.
The letter T can be used to indicate the beginning of the time interval. Dates can be formatted either with the hyphen, yyyy-mm-dd, or without, yyyymmdd. Likewise, the time can be written either hh:mm:ss or hhmmss. Whether you choose to use punctuation or not, four characters must be used for the year, two for the month, and two for the date. Two characters must be used for the hour, the minute, and the second, hhmmss. (year: 4, month: 2, day: 2, hour: 2, minute: 2, second: 2) The input is flexible because the parser is only looking for digits and ignoring the punctuation characters.
The search server will always start with the first four characters being the year and work towards the finest granularity.
A date-time range search that includes the boundary numbers is below:
Example:
variable = wrapper_function('(d.patient_date_of_birth:[20110701 TO 20110705])')
The above query returns results that have one of the following dates specified previously in the field date:
20110701, 20110702, 20110703, 20110704, 20110705
It is possible to write your search using relative dates and times. See Relative Date-Time Interval for more information.
COMBO
The COMBO keyword helps the composite (or concatenated) keys that were initially indexed to accelerate a search. For example, the parse table can define a new field upon indexing to concatenate the sets of last names and given names into one field, LnGn, which can then be searched as a single term:
Example:
variable = wrapper_function('(LnGn:smith, john)')
This replaces a previous lengthy search that would have to intersect two large sets in the index:
Example:
variable = wrapper_function('(LastName:smith GivenName:john)')
COMBO can use the indexed field LnGn to speed up the search. Often many names are composed of more than one word, e.g. Rip Sleepy van Winkle. COMBO automatically pairs each separate word in the last name with each separate word in the given name to use the pairwise indexes that were generated. Here the combinations are van Rip, van Sleepy, Winkle Rip, Winkle Sleepy. The COMBO keyword automatically generates all the pair combinations as an intersection sub-expression.
Example:
variable = wrapper_function('(LnGn:COMBO(van winkle, rip sleepy))')
The comma is used to separate the group of last names from the group of given names.
In addition, the COMBO function can be used in conjunction with metaphones and stems by the tilde operator, ~, immediately following the closing parenthesis of the COMBO function:
- field:COMBO(v1 v2, v3 v4)~M
- field:COMBO(v1 v2, v3 v4)~S
- field:COMBO(v1 v2, v3 v4)~
Combination indexes of type metaphone or stem must be specified in the parsetable.xml to make the combination index sets during data feeding so that they are available for the query system.
SET
The user can store the results of a previous query in a compressed bitmap as a set of hits in his or her session directory. The set can be used in subsequent queries via the keyword "SET", SET:SetName, where SetName is a name of a set stored in the user's Sessions/sess.ID directory. The CGI parameter &sessionid=ID must be present to identify which session contains the stored sets. The sessionid parameter is automatically added by the middleware based on the user credentials and the user does not need to enter the parameter when using sets.
Sets cannot be created with the Single report component of Report Builder; use compound reports to create sets.
Below the query finds all those with the last name Smith that are contained in the SET HighBP.
Example:
variable=wrapper_function('()LastName:Smith SET:HighBP')
See the Set Syntax Guide for more information on sets.
Administrators may use the Set Definitions page in Admin to create and manage sets.
FILTER
Data that is stored in the QuickTable can be accessed during a query search. The FILTER keyword contains a Boolean expression which targets only fields of a QuickTable.
The FILTER function is a parameter of a Boolean expression and uses the same operators: AND, OR, NOT, etc. It may appear anywhere in the general Boolean query expression. Any field names in the FILTER's Boolean expression must be fields of one (or more) of the QuickTables for the stores being searched.
The syntax is similar to the normal Boolean query expression, but free terms (those without a field name) are disallowed. Every term (or value expression in parentheses) must have an associated explicit field name that exists in the QuickTable.
The string search for QuickTable string fields has not been implemented because string field searches are adequately covered by the standard Perfect Search index.
Below, a hit occurs when both indicated values are in the QuickTable record.
Example:
variable = wrapper_function('()FILTER(year:1934 AND score:98)')
Below, the QuickTable field values must be in the specified interval:
Example:
variable = wrapper_function('()FILTER(year:[1930 TO 1940] score:[90 TO 100])')
In the example below, the year must be in listed values or in the session set named MyGoodYears. The set of year values was built previously and stored in a session. Inside a FILTER, a specified set must contain values from a QuickTable field. If more than one term is used for a single field, you must include parentheses around all the terms for that field, year:(IN(1921,1933,1949) OR SET:MyGoodYears).
Example:
variable = wrapper_function('()FILTER(year:(IN(1921, 1933, 1949) OR SET:MyGoodYears))')
Symbols, Symbol Map
Often a list of either field names or values recurs in query expressions. For example, if the same type of data has been given different field names, a search must be done to include all the field names that contain the same data: age, patient_age, age_of_patient, age_patient. To facilitate data entry, the administrator can define a symbol map where a named symbol can resolve to the appropriate list of words or values.
In the query language, symbols are designated with angle brackets,"<>". Field symbols may only be used inside the FOR operator. Value symbols may only be used inside the IN operator. Symbol resolution effectively injects more parameters into the operator's parameter list.
Symbol names contain two parts, a category and a variable name, and are separated by a period. The category is used as a name space and a description and is a prefix to the variable name. The variable contains the list of values (field names, clinical codes, etc.) that the administrator can add to or delete from: <category.variable_name>, <labs.acl>.
Some symbols are global and do not have a category prefix: <variable_name>.
Variable names and category names may use underscores and alphanumeric characters. The period is reserved as the separator between them and should not be used as part of either name. The names are treated as case insensitive and the system converts them to lowercase. Typical entry is lowercase:
Example:
variable=wrapper_function('()FOR(snomed.s.p.patient.<sections.assessment_names>):IN(<snomed.diabetes_codes>)')
In the example above snomed.s.p.patient. is used to refer to the concatenated fields defined in the symbol <sections.assessment_names>. Sections being the category and assessment_names being the variable name referring to several fields. The second half of the expression uses snomed as the category and diabetes_codes as the variable name.
After symbols are created, not only can they be used as part of the Boolean expression, but they can be used in the fields parameter.
doclang:value
The Boolean search field 'doclang', document language, can be used to limit searches to documents with specific languages.
Example:
variable = wrapper_function('()query_expression(doclang:(eng))')
The doclang field can be searched with the Boolean term OR. The Boolean term AND returns no hits because each document only has one doclang assigned.
Example:
variable = wrapper_function('()query_expression(doclang:(eng OR zho))')
Basic Query Parameters
https://<appliance_ip>/search?q=Query&fields=None&limit=-1&store=None&outputset=None&advanced-options=None&facets=None&format=XML&start=0&report=None&sample=None&sort=asc&lang=en&snippets=None
All of these parameters apply to compound reports or URL searches. These parameters are preset in Single report; therefore, this section does not apply when writing a single report with Report Builder.
A query must include either a q parameter or a wq parameter, but all the other parameters are optional and have predefined defaults. They can be used to modify the main query as needed and multiple parameters can be included in each query line. The CGI parameters are UTF-8 encoded.
- q = (query)
- fields = (string1,string2,string3)
- Xpath
- Regular expressions
- limit = (number)
- store = (number1,number2,number3)
- outputset = (True/False/string)
- advanced_options
- facets = (beginning, end, gap)
- countby = (string)
- format = (string)
- start = (number)
- onspace, onref, onsortval = (string)
- report = (exacttotal/approxtotal)
- sample = (number)
- sort = (string asc/desc)
- lang = (language)
- snippets = (string)
Know that there is some risk involved with some parameters when Wrapper Functions are not used. In most cases the risk is slowing the search significantly. Using the former Query().execute() method can still be used to write queries, but using the wrapper functions is encouraged when possible.
q
Any term (or phrase) that the user is searching for is referred to as the q parameter. The most basic query type is below and searches for all occurrences of the word computers. See the query expression section for greater detail on all aspects of the query expression.
Example:
variable = wrapper_function('()computers')
Fields
The fields parameter indicates the information to return for each item. Only fields that have been stated in the parse table and QuickTable fields (designated by a qtable. prefix) are available. Possible fields include uri, title, description, snippets, record, rawrecord, extract (designated with the prefix extract.), etc. Using rawrecord returns the original record without change. However, the use of record "sanitizes" the record and replaces some symbols with code: "<" becomes "<", ">" becomes ">", and "&" becomes "&". This guarantees that the data is always valid XML and displayed as part of the results without any possibility of interfering with HTML or style sheets.
Individual fields are separated by a comma.
In this example, the URI and title, weight (from the extract), and patient_id (from the QuickTable) are returned.
Example:
variable = wrapper_function('()query_expression', fields='uri, title, extract.weight, qtable.patient_id')
It is possible to retrieve the first time the URI was indexed as well as the most recent time the URI was indexed. To do so, specify the field names indextime and updatetime when writing the query. Below is an example of how to write a query using both of these fields.
Example:
variable = wrapper_function('()query_expression', fields='indextime, updatetime')
The returned value is the date and time specified in UTC.
Response:
indextime updatetime
0 2016-02-10 22:40:13Z 2016-02-10 22:40:13Z
1 2016-02-10 22:54:17Z 2016-02-10 22:54:17Z
...
Symbols can also be used as a field parameter.
Example:
variable = wrapper_function('(query_expression)', fields='<symbolName>')
There is a shortcut to the fields displayed in the IMAT Solutions Report Builder. See CLINICAL_REPORTS_FIELDS for more information.
Xpath
Xpathing is querying a specific portion of the XML records to be returned in the hit list. This is specified using 'fields=record.' followed by an xpath expression that specifies the portion of the record to be returned. These kinds of xpath expressions are now available both in the query ('fields=...') and in the parsetable when specifying conditional indexing. The most common use for this is to select data not found in extracts.
Following are some examples of xpath expressions that could be used.
Examples:
In this example, notice the need for double quotes around the string "icd10" because single quotes were initially used around the fields string:
variable_name=get_hits('()query_expression', fields='record.problems/concept/codes/code[@type="icd10"]')
The code snippet below returns the full CXML record:
record.cxml
This returns all type="problem":
record.concept[@type="problem"]/text
Finally, this returns all type=problem, polarity=p, certainty=c, subject=patient and has a child <codes> whose child <code> has an attribute type=icd9:
record.concept[@type="problem" and polarity="p" and certainty="c" and subject="patient" and codes/code[@type="icd9"]]/text
Regular Expressions
Regular expressions can be used in the fields parameter. Using regex can speed up a query significantly or reduce the need for two queries. Regular expressions are also advantageous in that it is possible to retrieve information that spans multiple xpaths or to further refine results when the smallest possible xpath returns more data than desired.
To format regex in the fields parameter, enter a custom label, a field name (or record section), and the regular expression Perl style. The custom label is assigned by the user while writing the query. Use a ~ for the separator character. The flags g and i are for global and ignore case, respectively. All examples below are shown as they'd be entered into the search bar of your browser.
Example:
&fields=MyLabel~record.document~/PV2-23-1[^:]*: ([^\r\n]*)/gi
Match groups can be created. MyLabel, m1, and m2 are decided by the user at the time of writing the query. Below the example shows match groups.
Examples:
&fields=Label.m1.m2~~/MyRegEx ([A-Za-z]*) +([0-9]*)/g
&fields=MyLabel.fname.ssn4~~/Hello +([A-Za-z]*) +([0-9]*)/g
CSV Response: Pipe-Caret delimited inside cell
Ralph^1234|William^5678|John^9012
XML Response
<MyLabel fname="William" ssn4="5678"/>
<MyLabel fname="John" ssn4="0912"/>
Use a leading backslash, \, if you need to escape these characters in your code: pipe, |; caret, ^; or backslash, \.
Limit
Limit is used to specify the number of results that are returned in the response. Report Builder runs faster, and the user finds the hits easier to manage if a limit is defined in the search. The default value for limit is -1 and returns all hits. Use caution when using the default limit, because it may use too many system resources.
Example:
variable = wrapper_function('()query_expression', limit=20)
Store
Stores are specific sets of data created when the data is indexed. Queries can be limited to search in specific data stores by adding either the store parameter or the space parameter. The two parameters provide similar functionality, but the store parameter is preferred. If no store numbers are listed, the default is to query all data stores. The data stores are referred to by number and are comma-separated when more than one is listed.
Example:
variable = wrapper_function('()query_expression', store=2)
When using facets, the store parameter is required. Multiple stores may be used with facets, but they also must be entered as a store string: store="1,2,3".
It is possible to create a group of stores to search by instead of entering each store name. To initially set up store groups, a change must be made in Advanced Configuration in the Admin tile. If assistance is needed in configuring this file, please contact professional services. To create a group of stores, create a group name and set it equal to the predefined store names. After those values have been assigned, it is possible to write the query using simply the group name.
The following two queries return the same results. In the case below, AuditLogSpace has been created to include auditLog1, auditLog2, and auditLog3.
Example:
variable = wrapper_function('()query_expression', store='auditLog1, auditLog2, auditLog3')
variable = wrapper_function('()query_expression', store='AuditLogSpace')
Outputset
Using outputset creates sets that the user is able to create clickable charts and graphs from. Set outputset to True to generate a default output set or assign it a name. See the Set Query Syntax Guide for more information on sets.
Example:
variable = wrapper_function('()query_expression', outputset='setName')
Advanced_options
This parameter is for intermediate or advanced users. Advanced_options uses Pandas to simplify charts and is a dataframe for any object to pass through and overrides the defaults to pandas.read_csv. See this site for better reference on possible uses of advanced_options.
Example:
variable = wrapper_function('()query_expression', advanced_options={'dtype':{'extract.patient_id': numpy.object_}})
Facets
Facets are organized perspectives of data. The data is displayed in subsets with counts. Not only is analyzing data easier, but it also creates a foundation for creating graphs. When creating facets, include a beginning number, an ending number, and a gap number. The gap creates the bin in which the counts are grouped. Precede the faceting range with a field name and the word range. See the faceting guides for more information.
More than one facet may be entered into the query line, creating a table for each facet in the output.
Example:
variable=get_facets('()query_expression', facets='field_name:range(10, 55, 15)', store=30)
Countby
The countby parameter counts all distinct values within a field found in the QuickTable. It is important to note that the field must be in the QuickTable.
When using countby with parameters, the distinct value is used for the count rather than the total number of items in the field. For instance, if there were 15 records in the QuickTable field, but only 3 of them had distinct values in the PatientIDN field, the bin count would be 3.
Example:
variable = wrapper_function('()query_expression', countby='PatientIDN')
Format
The format parameter allows the specification of the format that results are returned in. The default format is XML, but can also be returned as CSV.
Example:
variable = wrapper_function('()query_expression', format='csv')
The parameters from Start to Snippets are not part of any wrapper functions. Using them creates risks, mostly in the form of significantly slowed searches. Queries, as they would be entered into the URL bar of a browser, are given as examples in this section. Always replace <appliance_ip> with a correct IP address, omitting the <> symbols. Always use the desired terms for the search instead of query_expression.
Start
Start determines the beginning hit result in the response and is typically used for pagination of results in a search interface. When paging through the list of hits, it is often easier to view several small result lists rather than one large list. Assigning a start value allows the user to omit the hits already viewed. A start of 100 returns the search results after skipping the first 100 hits. If no start value is specified, the hits begin at (0).
URL Example:
https://<appliance_ip>/search?q=query_expression&start=100
Onspace, Onref, and Onsortval
Onspace and onref are used together for pagination and can only be used with a Boolean query. However, while paging using start always sorts by the most recently indexed records, onspace and onref use space and reference IDs for paging (space-ref paging). This is beneficial because paging using start does not necessarily return the same results each time with constant feeding of new material. Because new indexes and merge activity could change the order, it is unlikely that the first 100 hits will remain the same. With the new paging, the hits are ordered by reference number, so the first 100 hits are always the first 100.
Use onspace=0 initially as a parameter to tell the system that you wish to use space-ref paging. If you do not specify a value for onref, then the system defaults to 0.
URL Example:
https://<appliance_ip>/search?q=()tachycardia&limit=50&onspace=0
The system automatically provides the reference number in the response. Use the ref number and space provided in the HTTP response header: x‑PS‑on‑space:100 and x‑PS‑on‑ref:52. They can also be found below the final hit in the response to the query.
Response:
<hits>
<hit>
...
<hit>
</hits>
<paging onspace="100" onref="12345" onsortval="20120405"/>
URL Example:
https://<appliance_ip>/search?q=()tachycardia&count=50&onspace=100&onref=12345
The onsortval parameter is used for paging during a sorted output that spans multiple pages and thus requires multiple continuation queries. It is used with the sort, onspace, and onref parameters. Define the field for sorting and paging by using the sort parameter, sort=d.dateofservice. The format for onsortval is yyyymmddhhmmss. The default is an empty string. The value is stored in the HTTP response header of the previous page as the parameter value of x‑PS‑on‑sortval.
URL Example:
https://<appliance_ip>/search?q=()tachycardia&limit=50&onspace=100&onref=12345&onsortval=201501405&sort=d.date_of_service
Report
Report has two settings that can be used: exacttotal (exact total) and approxtotal (approximate total). The response provides the number of records that meet the query criteria. The exacttotal runs the query to the end to find exactly how many results fulfill the query. Searching for an exact total requires searching each record available and takes longer to execute. The approxtotal uses an algorithm to estimate the total from the sample parameter. The approxtotal is recommended because it requires less processing power and search time to run the query.
Approxtotal is not available in all releases after the Version 8 series.
URL Example:
https://<appliance_ip>/search?q=query_expression&report=approxtotal
Sample
The sample parameter is used to calculate the approxtotal from a known sample. Setting a sample size determines how many records must be gathered before the server can quit searching. If a sample size is set at 10,000, the server has to gather only 10,000 records rather than possibly millions of records. If approxtotal is used, it is calculated based on an algorithm using the number of hits found in the sample. A small sample runs faster but could return a less accurate estimate.
URL Example:
https://<appliance_ip>/search?q=query_expression&report=approxtotal&sample=10000
Sort
The sort parameter is used to sort the resulting data set. The string should be a valid numeric or date field name to sort by. The results can be sorted ascending (asc) or descending (desc); ascending sort is default. When running a sort, the report parameter is ignored. The limit and start parameters can still be used for paging sorted output. Sort can only be used on one field at a time.
Sort is only available for numeric, date, or date-time fields. These must be specified in the parsetable.xml file.
A range may be specified with the field to limit the extent of the search. When no range is specified for the field, all the results from that field are sorted. If the field has a specified range, the results found within that range are sorted.
URL Examples:
Descending sort:
https://<appliance_ip>/search?q=query_expression&sort=lastmodified desc
Ascending sort with specified range that has year precision (not necessarily sorted by month):
https://<appliance_ip>/search?q=query_expression&sort=lastmodified:[2011 TO 2012] asc
Ascending sort with specified range that has day precision (not necessarily sorted by hour):
https://<appliance_ip>/search?q=query_expression&sort=lastmodified:[2011-01-01 TO 2011-12-31] asc
No Range ("FieldName" is a parameter specified by the user):
https://<appliance_ip>/search?q=query_expression&sort=FieldName asc
For dates, the appliance supports Lucene syntax for date-time interval expression. If dt1 and dt2 are internet date-times (like 2010-03-15T11:30:00), then dt1 and dt2 can have less precision, e.g. [2006-02 TO 2007-06], and a partial sort to this precision is executed. It is referred to a partial sort because it sorts only to the day, month or year specified. Without sorting to greater detail (sorting by hour when the date was the specified sort), the server processes the request faster. Dates can be formatted yyyy-mm-dd or yyyymmdd, but must contain four digits for the year, two for the month, and two for the date:
- [2011-02-01 TO 2012-06-30] has day precision (not necessarily sorted by hour)
- [2011-02 TO 2012-06] has month precision (not necessarily sorted by day)
- [2007 TO 2012] has year precision (not necessarily sorted by month)
For decimal numbers, precision control is also available to the level for which the parse table is configured. The number with the most decimal places in the sort range interval determines the precision:
- [1 TO 99] sorts at integer precision
- [1.0 TO 99] sorts at tenths precision
- [1.00 TO 99] sorts at hundredths precision
URL Example:
https://<appliance_ip>/search?q=query_expression&sort=lastmodified:[1.0 TO 60]
Language
The language parameter in the query string is used to determine stems and stop-words. The string to determine the language may be a two-letter code, three-letter code, or language name officially listed in the ISO-639 specifications. If the language code used in the query does not match any listed in the SearchServer.conf file, the first language listed in the languages section is used; it is English (en) when there is no list.
URL Example:
https://<appliance_ip>/search?q=query_expression&lang=en
Snippets
Snippets are strings from the document that give the user a short preview of the text around the query term to help determine the relevance of the document.
There are a few parameters to be used to help determine how much snippet information is returned.
Parameters
- fields={string}
- snippetlength={number}
- snippetcount={number}
URL Example:
The fields parameter must contain the word "snippets" for snippets to be returned. However, this does not mean that the field name must be "Snippets" or contain the word as part of the name. See the fields parameter description for more information.
The following example searches for the Boolean terms diabetes and alcohol. The response contains the uri, the title, and snippets from anywhere in those documents where the terms occur.
URL Example:
https://<appliance_ip>/search?q=()diabetes alcohol&fields=uri,title,snippets
Snippet Length
To change the number of characters returned for each snippet, add a snippetlength parameter to the query string. The default number of characters is 50 and the maximum is 5,000.
URL Example:
https://<appliance_ip>/search?q=query_expression&fields=snippets&snippetlength=75
Snippet Count
To change the number of snippets returned for each hit, add a snippetcount parameter to the query string. The default number of snippets is 3 and the maximum is 100.
URL Example:
https://<appliance_ip>/search?q=query_expression&fields=snippets&snippetcount=5
URL Searches
Searches can be done by entering the CGI request into the search bar of your browser. These can also be called browser searches, URI searches, API searches, or search server searches.
In the CGI (Common Gateway Interface) request string, the different parameters are separated by the ampersand symbol, &. The query CGI term, "&q=", is generally large; and the CGI string is typically transmitted into the search server via an HTTP POST protocol.
Formatting
- Begin each query by typing
https:/appliance_ip/search?. - Indicate the query expression with the q parameter,
q=. - Separate each parameter with the ampersand, &.
- Use quotes around phrases in the query expression; quotes are unnecessary around other string content, such as field names.
URL Example of Ranked and Boolean Query Expression:
https://appliance_ip/search?q=cholesterol plaque positive "heart attack" ("mortally high" AND "immediate concern")
The example below is a query that returns twenty mentions of the term "heart arrhythmia" beginning with the eleventh hit and reports the approximate total hit count using a sample size of 5,000. It returns the facility and search in stores 1, 2, and 3. Notice that the phrase "heart arrhythmia" is the only item that requires quotes.
URL Example:
https://appliance_ip/search?q="heart arrhythmia"&fields=extract.facility&store=1,2,3&count=20&start=11&report=approxtotal&sample=5000
When entering a facet query in the search bar of the browser, enter it as below:
URL Facet Example:
https://<appliance_ip>/search?q=query_expression&facets=field_name:range(begin:10, end:55, gap:15)
GUID and SUID
These are unique identifiers. They collect a list of all of the unique values that have been encountered within a specified field. Activate the functionality by defining a field to be used for this purpose in the parse table. After the GUID and SUID have been established in the parse table and quick tables, use them in your reports to quickly access a list of the unique values using the unique query. In the examples below, the field named facility has been defined as a SUID:
URL Example:
https://appliance_ip/search?unique=facility
Facets can also be used once GUIDs and SUIDs have been defined:
URL Example:
https://appliance_ip/search?facets=facility
To use GUIDs and SUIDs in Report Builder, it is possible to write it as a query line and then print the query, or, as below, to simply use it in a print function:
Report Builder Example
print(get_unique_values("facility")["facility"]) # This returns a list of all the values
print(get_unique_values("facility")) # This returns a dictionary
psfieldnames
All the field names that occur in a document are indexed. This allows the user to write a query to display all documents that contain a specific field. The feature is advantageous because it allows for verification that all records that should have a certain field actually do; it also helps identify all records that don't.
Write the query as below, replacing
Example:
(psfieldnames:<fieldname>)
The following query finds all records that contain the field patient_id. Records that contain data in that field appear in the results.
Example:
(psfieldnames:patient_id)
It is possible to search for records that do not contain information in that particular field. To do so, write a Boolean expression using the operator NOT. It is better to narrow the search by including at least one other term in the Boolean expression. The query below is searching for all records that do not contain information in the patient_id field that attend Intermountain Hospital:
(facilityname:"Intermountain Hospital" NOT psfieldnames:patient_id)
It is possible to use this function in Report Builder.
To use this function in Report Builder, it is necessary to specify psfieldnames as the field to search.
variable = wrapper_function('()psfieldnames:patient_id')
Weighted Queries
A weighted query differs from a ranked search because the user assigns the values to the terms rather than having the computer assign those weights. In addition, the q parameter can be used to specify a "hard" Boolean restriction to narrow the weighted query (wq parameter). A weighted query contains several terms with different weights attached.
The simplest query for a weighted query list is seen below (values determined by the user):
URL Example:
https://<appliance_ip>/search?wq=termA^2.3 termB^1 termC^0.75
Each term may be a single word (or field:word), a quoted phrase (or field:"phrase"), or a Boolean expression with parentheses. The caret character, ^, attaches weight to the search term. This weight can range from 0.0001 to 100. If a smaller weight than four decimal places, the parser rounds the input to four decimal places (22.00045 rounds to 22.0005). As per Lucene convention, the weight may be omitted, which causes the default weight of ^1 to be attached.
In this example, termB is treated as if it were written termB^1:
URL Example:
https://<appliance_ip>/search?wq=termA^2.3 termB termC^0.75
The weighted query sequentially runs each weighted term to the end of its set and increments a score accumulator by the term's weight value. Thus the separate weighted terms are effectively run as a union (logical OR). Hits that have more terms present tend to accumulate higher scores. The results are sorted by score in descending order. An exact total hit count is always returned. Because the weighted query has to run to the end of the search, it is inherently slow. Specifying fields to search rather than entire documents can help speed the query run time.
When using a weighted query, the entire q= parameter becomes a Boolean filter query. Parentheses are not required to indicate this. Only hits that pass the Boolean filter are accumulated for scoring.
A ranked search and a weighted-OR search cannot be run in the same query.
The weighted query search can only search one store at a time. If the store parameter is absent, the default is store=0.
WQM
WQM is a faster weighted query that avoids testing every listed term on each hit candidate. Weighted terms are listed by groups in parentheses. Groups are separated by the Boolean operator AND. Only one term from each group contributes to the score of a hit. Within each group, the terms are sorted by their weights. The hit candidate is tested sequentially starting with the highest weighted term. As soon as the candidate fulfills a term, the algorithm adds that term's weight to the score and then jumps to the next group and repeats the process; thus only one term from each group is contributing to the score of the hit. Lucene/Solr calls this algorithm the "disjoint-maximum", or "dis-max", weighted search. It runs considerably faster than the standard weighted search.
Example:
https://<appliance_ip>/search?wqm=(termA^2.3 termB^1 termC^0.75) AND (termD^0.3 termE^0.2 termF^0.75 ANY^0) AND (...)
In the example above, a wqm searches the first expression (termA, termB, and termC) and calculates the score based only on the term with the highest value. For instance, if termB and termC both occurred in the document but termA did not, the score assigned would be 1 instead of 1.75. The search would then move to the second expression (termD, termE, and term F) and assign a score in the same manner.
The ANY is a special keyword with the weight ^0. It is used when the user wants the hit even if the candidate fails on all other terms in the group. ANY must not occur in all the groups because at least one group must constrain the search. Each weighted term may be either a single word, a quoted phrase, or an arbitrary Boolean expression in parentheses.
AND (...) indicates that there can be as many groups added to this query as the user desires.
Hits are returned in order, beginning with the highest score.
Export Results Report to File
When outputting results to a file in the reports-path directory, there are two parameters that can be used.
Parameters
- outfile={FileName}
- format={string}
Outfile
The outfile parameter allows the specification of a file name. The FileName should be a simple name with no directory path.
Example:
Query&outfile=FileName
Format
The format parameter allows the specification of whether the file is exported as XML or CSV. XML is the default.
Example:
Query&format=xml